1952 년에 David Huffman 에서 의해서 고안된 Huffman coding 으로 불리는 텍스트 압축 똑똑한 프로그램이 있다.
The basic idea is that each character is associated with a binary sequence (i.e., a sequence of 0s and 1s).
기본 아이디어는 각 문자는 이진 나열과 관계가 있다.(즉 0 과 1 의 나열)
These binary sequences satisfy the prefix-free property: a binary sequence for one character is never a prefix of another character’s binary sequence.
이 이진 나열은 Prefix-free 특징을 만족한다: 한 문자의 이진 나열은 다른 문자의 이진 나열의 접두사가 절대 아니다.
It is worth noting that to construct a prefix-free binary sequence, simply put the characters as the leaves of a binary tree, and label the “left” edge as 0 and the ”right” edge as 1.
prefix-free 이진 냐열을 구축하고 단순히 문자들의 이진 트리의 잎 노드로 두고 왼쪽 에지를 0 으로 오른쪽 에지를 1 로 둔다.
The path from the root to a leaf node forms the code for the character at that leaf node.
루트에서 잎으로의 패스는 잎노드의 문자에 대한 코드를 이룬다.
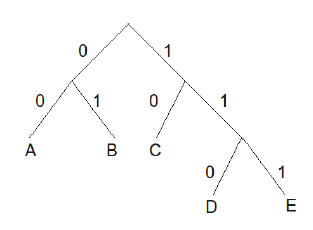
For example, the following binary tree constructs a prefix-free binary sequence for the characters fA, B, C, D, Eg:
예를 들어, 다음 이진 트리는 prefix-free 이진 나열을 이룬다. 다음 문자들에 대한 fA,B,C,C,
That is, A is encoded as 00, B is encoded as 01, C is encoded as 10, D is encoded as 110 and E is encoded as 111.
즉 A 는 00 으로 B 는 01 로 C 는 10 으로 D 는 110 으로 E 는 111
The benefit of a set of codes having the prefix-free property is that any sequence of these codes can be uniquely decoded into the original characters.
이 prefix-free 특징을 가지는 코드의 집합의 장점은 이 코드들의 나열은 유일하게 원문으로 풀수 있다는 것이다.
Your task is to read a Huffman code (i.e., a set of characters and associated binary sequences) along with a binary sequence, and decode the binary sequence to its character representation.
할 일은 Huffman code 를 읽어서( 즉 문자들의 집하고 관계된 이진 나열) 이진 나열과 더불어, 이 이진 나열을 관련된 문자들의 포현을 디코딩하는 것이다.
입력 5 A 00 B 01 C 10 D 110 E 111 00000101111 출력 AABBE
출처: 채점 데이터: