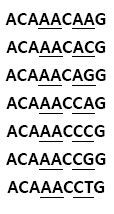
컴퓨터를 이용하여 해결하는 흥미로운 작업 중 하나는 DNA 서열과 같은 생물학적인 자료를 분석하는 것이다. 하나의 DNA 가닥은 뉴클레오티드인 아데닌, 사이토신,구아닌, 티민으로 이루어진 체인이다. 이들 네 개의 뉴클레오티드는 각각 A, C, G, T 로 나타낸다. 따라서 DNA 가닥은 이들 네 문자의 문자열로 표현될 수 있다. 이 문자열을 DNA 서열이라 부른다.
DNA 가닥의 어떤 위치에 있는 뉴클레오티드가 정확하게 무엇인지 결정할 수 없는 경우가 있다. 이러한 경우, 이 가닥의 DNA 서열의 미확인 뉴클레오티드를 나타내는데 문자 N 을 사용한다. 달리 말하면, N 은 A, C, G, T 중 임의의 문자 하나를 위한 와일드카드 문자이다. 한 개 이상의 N 이 있는 DNA 서열을 불완전서열이라 부르고, 그렇지 않은 문자열을 완전서열이라 부른다. 불완전서열에 있는 N 각각에 대하여 이를 네 개의 뉴클레오티드 중 하나로 대체하여 완전서열을 얻을 수 있으면, 이 완전서열을 주어진 불완전서열과 일치한다고 말한다. 예를 들어, ACCCT 는 ACNNT 과 일치하지만 AGGAT 는 일치하지 않는다.
연구자들은 네 개의 뉴클레오티드를 다음과 같이 영문자 순서대로 순서를 정한다: A 는 C 보다 앞에 나오고, C 는 G 보다 앞에 나오고, G 는 T 보다 앞에 나온다. DNA 서열에서 각 뉴클레오티드가 오른쪽 옆에 있는 뉴클레오티드와 같든지 혹은 오른쪽 옆에 있는 뉴클레오티드 보다 이전 순서의 문자이면, 이 서열은 형태-1 로 분류된다. 예를 들어, AACCGT 는 형태-1 이지만 AACGTC 는 아니다.
일반적으로 형태-j 서열은 다음과 같이 정의된다: 이 서열이 형태-(j-1)이든지 혹은 어떤 형태- (j-1) 서열 하나와 어떤 형태-1 서열 하나를 연결한 것이면 이를 형태-j 서열이라 윱 예를 들어, AACCC, ACACC 와 ACACA 는 형태-3 서열이지만 GCACAC 와 ACACACA 는 형태-3 서열이 아니다.
연구자들은 사전에 단어들을 나열하는 순서인 사전식 순서대로 DNA 서열들의 순서를 정한다. 따라서 길이 5 인 형태-3 서열들 중 첫 번째 순서의 서열은 AAAAA 이고 마지막 순서의 서열은 TTTTT 이다. 다른 예로 불완전 서열 ACANNCNNG 를 고려해보자. 이 불완전서열과 일치하는 형태-3 서열들 중 첫 번째부터 순서대로 7 개를 나열하면 다음과 같다:
입력 9 3 5 ACANNCNNG 출력 ACAAACCCG 입력 5 4 10 ACANN 출력 ACAGC
long long a;
scanf("%lld",&a);
printf("%lld\n",a);
Pascal 에서는 Int64 자료형을 사용해야 한다. 이 형의 자료를 다루는데 특별한 명령어는 필요하지 않는다.
출처: Asia-Pacific Informatics Olympiad 2008