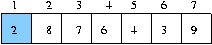
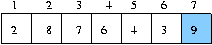
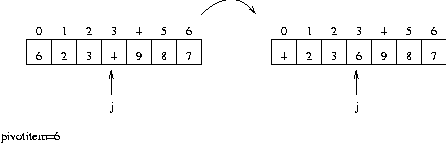
즉 첫 번째 원소가 자리 자리를 찾아 간다는 것은 해당 원소보다 작은 데이터가 앞으로 큰 데이터는 뒤로 보낸다는 의미이다.
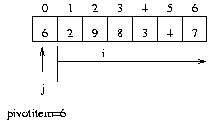
왼쪽 그림에서 0 번째 데이터 6 을 4 번째에 위치시키고 6 보다 작은 데이터를 왼쪽에 큰 데이터를 오른쪽에 위치시키는 문제이다.
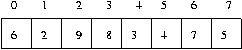
|
----> |
|
차례
1. partition 방법
2. quick sort 구현
3. 왜 quick 인가?
4. library 로 구현하기
5. 분석
이제까지 알아본 정렬(bubble, selection,... ) 가장 큰 데이터 혹은 작은 데이터를 앞 혹은
뒤로 보내는 방법의 정렬이었다.
|
배열에서 첫 번째 원소를 자기 자리를 찾아 보내는 게 문제이다.
즉 첫 번째 원소가 자리 자리를 찾아 간다는 것은 해당 원소보다 작은 데이터가 앞으로 큰 데이터는 뒤로 보낸다는 의미이다. 왼쪽 그림에서 0 번째 데이터 6 을 4 번째에 위치시키고 6 보다 작은 데이터를 왼쪽에 큰 데이터를 오른쪽에 위치시키는 문제이다.
|
(풀이)
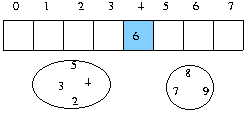
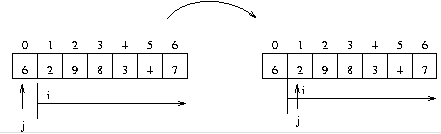
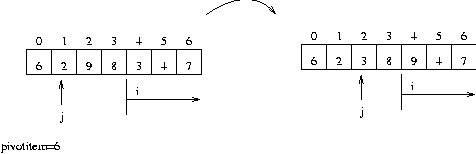
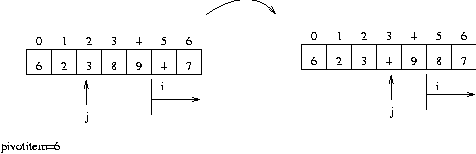
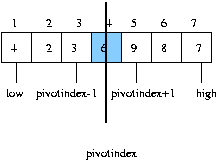
0 번째 데이터를 pivotitem 변수로 j 는 0 i 는 j+1 에서 끝까지 pivotitem 과 i 번째 데이터와 비교해서 i 번째 데이터가 작으면 j 를 1 증가후 i 번째 데이터와 j 번째 데이터를 교환 j 번째 데이터와 0 번째 데이터를 교환하면 끝...
예로서
시작 상태
1 2 3 4 5 6 7 8 9 10 | void quick(int low,int high){ int pivotindex; if (low < high){ partition(low,high,&pivotindex); quick(low,pivotindex-1); quick(pivotindex+1,high); }} |
selection sort 의 한 패스
6 번의 비교 만에 제일 작은 데이터를 제일 처음으로
quick sort 의 한 패스
6 번의 비교 만에 제일 처음 데이터를 정렬
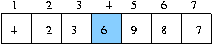
첫 단계에서는 비교회수는 두 방법다 6 번의 비교가 일어난다. 하지만 선택정렬의 다음 단계에서는 5 번의 비교로 다음 작은 데이터를 2 번째 위치로 옮기지만 quick 정렬은 4 를 소트할 때 4 위의 데이터는 더 이상 비교할 필요가 없므로 2 번의 비교만에 제자리에 놓을 수 있다.
한 번에 반씩 줄어들 때 log 성질이라하고 , 한 번은 Q 같고 다음에 반씩 줄어들 때 nlogn 성질 이라한다.
(보기2)아래 데이터로 선택정렬과 quick 정렬을 비교해 보자.
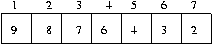
selection sort 의 한 패스
6 번의 비교 만에 제일 작은 데이터를 제일 처음으로quick sort 의 한 패스
6 번의 비교 만에 제일 처음 데이터를 정렬선택정렬의 다음 단계에서는 5 번의 비교로 제일 작은 데이터를 제자리에 위치시키고, quick 정렬도 첫 단계에서 첫 번째 데이터가 제일 뒤로 가서 자리를 잡아서 두 번째 단계에서 비교의 횟수를 줄일 수 없다.
quick 정렬은 이미 (거의)소트되어 있거나 역순으로 소트되었을 때는 , 선택정렬과 bubble 정렬과 비교해서 속도를 향상 시킬수 없다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | #include <stdio.h>#include <stdlib.h>int cmp(const void *va,const void *vb){ int *a,*b; a=(int *)va; b=(int *)vb; return *a - *b;}int main(){ int ia[]={6,2,9,8,3,4,7}; // 원소 7 개를 가진 정수형 배열. 오름차순 정렬하기 int i; qsort(ia,7,sizeof(ia[0]),cmp); for(i = 0;i < 7;i++){ printf("%d ",ia[i]); } printf("\n"); } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #include <stdio.h>#include <stdlib.h>struct s { int num; int score; char name[20];};int cmp(const void *va,const void *vb){ struct s *a,*b; a=(struct s *)va; b=(struct s *)vb; return a->score - b->score;}int main(){ int i; struct s hak[]={ {1,10,"lee"}, {2,30,"park"}, {3,20,"kim"}, {4,15,"cho"} }; // 원소 4 개를 가진 hak 배열. score 순으로 오름차순 정렬 qsort(hak,4,sizeof(hak[0]),cmp); for(i = 0;i < 4;i++){ printf("%d %s %d\n",hak[i].num,hak[i].name,hak[i].score); } printf("\n"); } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | int cmp(const void *va,const void *vb){ char **p,**q; p = (char**)va; q = (char**)vb; return strcmp(*p,*q);}int main(){ char *p[]={"abc","def","kkk","azaz"}; qsort(p,4,sizeof(p[0]),cmp); for(int i=0 ; i < 4 ;i++){ printf("%s\n",p[i]); }} |
Unstable 6 6 3 9 9 6 7 7 4 O(nlogn)[푼 후(0)]