이진 검색(binary search)
(1) 이진 검색이란?
이진 검색이란 데이터가 정렬되어 있을 때 아주 강력하게 사용할 수 있는 검색
방법이다.
예를 들어, 운동장에 전교학생이 일렬로 키 순으로 서 있다고 하자.
선생님이 이름이 홍길동이란 학생을 찾고자 하는데
선생님이 이 학생의 얼굴을 모르지만 키가 얼마인지를 안다고 하자
이 경우 앞에서 혹은 뒤에서 순차적으로 차례로 검사하는 것 보다 대충 중간정도에 서 있는 학생에게 가서
홍길동인지 아닌지를 물어보고 이 학생이 홍길동이 아니라면 키가 얼마인지를 물어보고 이 학생이 홍길동
홍길동보다 작으면 이 학생 뒤에 홍길동이 있다는 이야기이므로 앞 학생의 모두를 한 번에 버릴수
있는 방법이다.물론 이 학생이 홍길동 보다 커다면 뒤에 있는 학생들 모두는 홍길동일수
가 없다는 말이다.
(2) 이진 검색의 구현
low , mid ,high 세개의 변수를 사용한다.
- low 변수는 찾고자 하는 데이터 구간의 첫 위치를 가진다.
- high 변수는 찾고자 하는 데이터 구간의 마지막 위치를 가진다.
- mid 변수는 low , high 의 중간 지점 즉 (low+high)/2 값을 가진다.
(보기)아래 그림과 같이 데이터가 오름차순 정렬되어 있고, 찾고자 하는 단어가 60 이라
하자.

(풀이)
단계 1----------
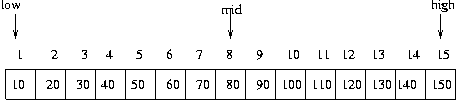
- low = 1
- high= 15
- mid=(1+15)/2 = 8
8 번째 데이터와 60 을 비교하니 60 이 작으므로 아래 구간이 데이터가 있거나
없거나 하다는 의미이므로 low 는 변함이 없고 high 값만 mid - 1 로 변경
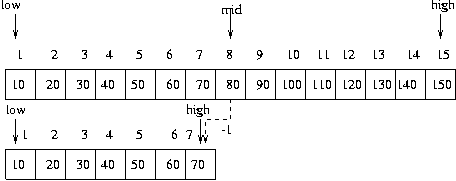
단계 2----------
- low = 1
- high= 7
- mid=(1+7)/2 = 4
4 번째 데이터와 60 을 비교하니 60 이 크므로 , 위 구간에 데이터가 있거나 없거나
하다는 의미이므로 low 가 mid + 1 로 변경되고 high 는 변함이 없음
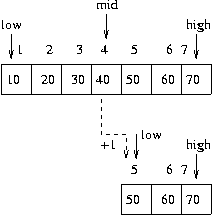
단계 3----------
- low =5
- high= 7
- mid=(5+7)/2=6
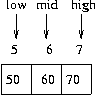
6 번째 데이터 60 에 찾고자 하는 데이터 존재###
정리하면 , 데이터가 오름차순 정렬되어 있다고 할 때
- 찾고자 하는 데이터가 중간값보다 커다면
- low 값을 mid + 1 로
- 찾고자 하는 데이터가 중간값보다 작으면
- high 값을 mid - 1 로
그러면 이진 검색에서 데이터가 존재하지 않는 경우의 검사는 어떻게 할까?
(3)데이터가 존재하지 않는 경우의 검사
low 가 작고 high 가 크다며 아직 두 개의 구간에서 찾는 데이터가 존재할 가능성이
있지만 , 만약 low 가 high 보다 커지면 더 이상 찾고자 하는 데이터는
없다는 의미가 된다.
위에서 든 보기로 검색 데이터를 45 로 하고 과정을 해 보는 것은 숙제로 남겨둘 테니
직집 해보기 바람.(^^)
(4)성능
데이터수가 1000 개일 때 순차검색에서는 최악의 비교회수는 약 1000 번이 된다.
평균 500 번의 비교가 일어나지만 이진 검색에서는 최악의 경우에도 10 번의 비교만으로 데이터가 있는지를
판단할 수 있다.
자료의 수가 많아지면 질수록 순차 검색과 이진 검색의 속도는 차는 더 커지게 될
것이다.
비재귀 소스| 재귀 소스
library로 사용하기
#include <stdio.h>
#include <stdlib.h>
#include <search.h>
int cmp(const void *va,const void *vb)
{
int *p,*q;
p = (int*)va;
q = (int*)vb;
return *p - *q;
}
int main()
{
int ia[]={2,4,6,8,10};
int key=8;
int *p;
//bsearch(찾을데이터, 배열의시작주소,배열개수,한배열의바이트수,함수포인터)
//찾고자 하는 데이터가 존재하면 해당데이터의 실제 주소
//없으면 NULL
p =(int*) bsearch(&key,ia,5,sizeof(int),cmp );
if ( p ) {
printf("found in %dth\n", p - ia);
}else {
printf("not found...\n");
}
return 0;
}
출처:dovelet